Fine-tuning is useful. It is also one layer.
A lot of interesting AI work sits outside the loop of downloading a base model, preparing a dataset, running a trainer, and publishing a checkpoint. That loop matters. It is not the whole stack.
There are projects inside runtimes, kernels, tokenizers, KV caches, quantization, device deployment, diffusion samplers, robot data, sensor models, local memory, world models, and evaluation harnesses.
These areas are less glamorous from the outside because the outputs are often benchmarks, traces, diagrams, failure cases, and repos instead of one clean demo.
Good. That is where the work gets interesting.
The useful question is not "what can be fine-tuned?" The useful question is "which layer of the AI stack is still poorly understood, poorly measured, or poorly tooled?"
The worthwhile project areas beyond fine-tuning are usually the ones with real constraints: memory, latency, data quality, controllability, embodiment, privacy, evaluation, and deployment. The model is part of the system, not the whole system.
Why Fine-Tuning Is Only One Layer
Fine-tuning is a behavior-change tool. It can improve domain style, task alignment, structured output, tool use, or specialized reasoning when the data is real and the evals are honest.
But it does not answer many of the hardest engineering questions.
- Runtime: how the model actually executes, allocates memory, stores the KV cache, samples tokens, and uses the hardware.
- Edge: what still works when bandwidth, battery, thermals, and offline behavior become first-class constraints.
- World modeling: whether a model can learn useful predictive structure from video, sensors, and actions rather than text alone.
- Control: how generated media follows masks, poses, depth maps, edits, constraints, and temporal consistency.
- Embodiment: how models behave when cameras, actuators, calibration, delay, and contact physics enter the room.
- Memory: how context is captured, indexed, retrieved, consolidated, redacted, and permissioned over time.
- Evaluation: how systems fail under stale context, slow tools, broken networks, weird users, and real latency budgets.
A project direction becomes technically interesting when it has hidden constraints, measurable failure, and a reusable codebase. That is the useful filter.
Technical interest = hidden constraint + measurable failure + reusable code
A Systems Example: Rust Edge World Model Lab
One useful composite example is a Rust edge world-model lab. It connects a low-level runtime, device constraints, small multimodal models, local memory, and latent predictive models.
The point is not Rust for the sake of Rust. The point is that edge AI makes memory layout, ownership, allocation, batching, CPU/GPU transfer, quantization, and deployment visible. Frameworks hide those details until a device starts dropping frames or burning battery.
The interesting layers look like this.
Runtime layer
Tokenizer plumbing, tensor layout, attention, KV cache, quantized matmul, sampling, and benchmark traces.
Edge layer
Small VLMs, ASR, embeddings, local storage, NPU/GPU execution, offline behavior, battery, and thermal limits.
World-model layer
Latent prediction over video, sensors, and actions. The output is not only a generated frame, but a representation that helps planning or anomaly detection.
Measurement layer
Latency, memory pressure, tokens per second, frame rate, battery drain, retrieval quality, and task failure under noisy inputs.
Project Directions Beyond Fine-Tuning
The categories below are a map of areas where the code, measurements, and failure modes are interesting.
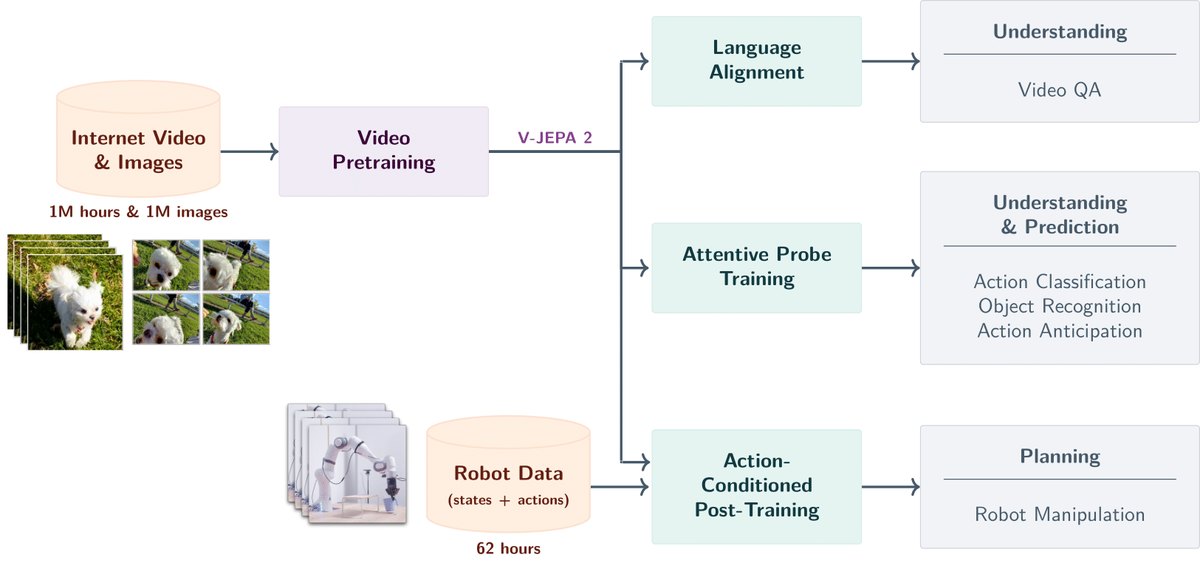
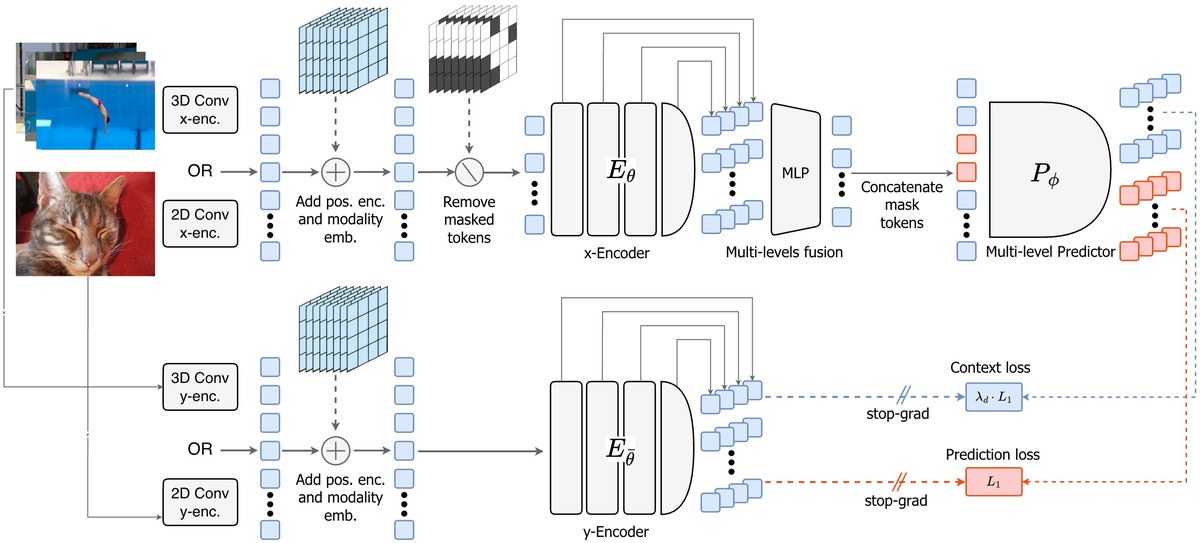
V-JEPA 2
Source image from facebookresearch/vjepa2. The useful part is the pretraining and action-conditioned loop, not the paper abstract.

FLUX
Source image from black-forest-labs/flux. Diffusion is still a systems topic when you expose control and sampling.
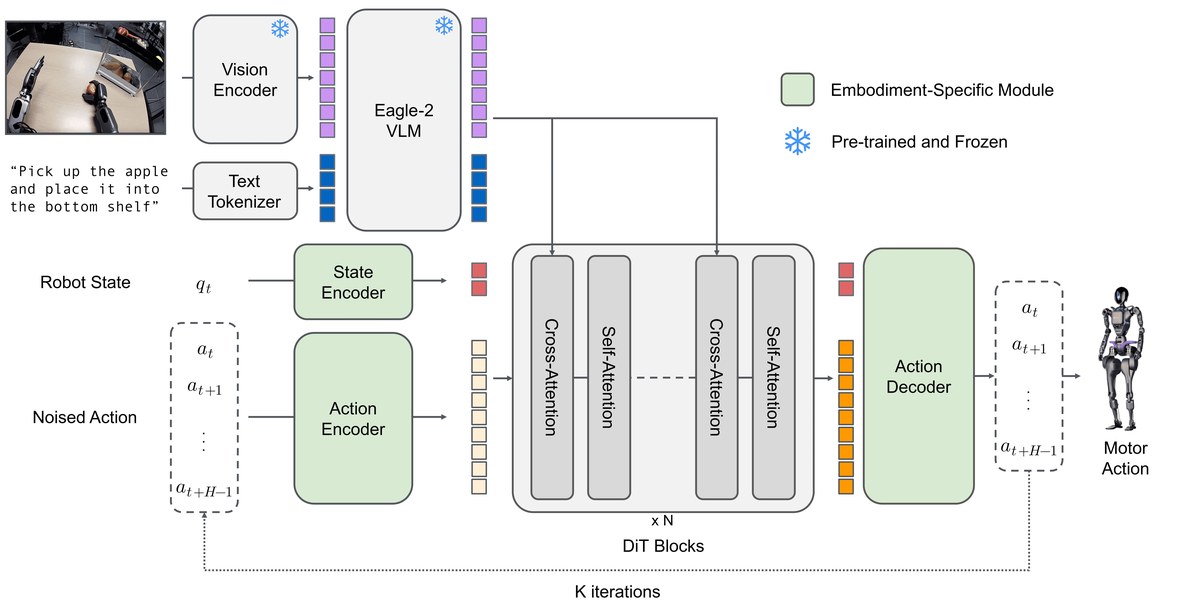
LeRobot
Source image from huggingface/lerobot. Robotics makes latency, data, calibration, and policy failure impossible to hand-wave.
{kind=link}
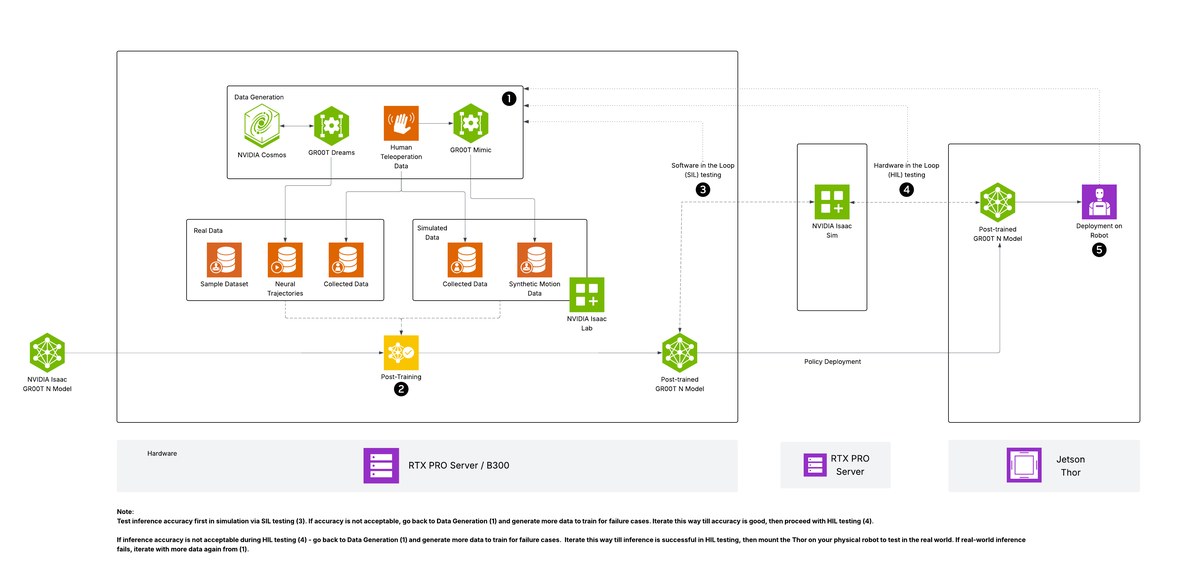
Isaac GR00T
Source image from NVIDIA/Isaac-GR00T. Physical AI is increasingly a full data, model, deployment, and evaluation stack.
{kind=link}
Rust Tiny Inference Engine
Explores: weight loading, tokenization, attention, KV cache, sampling, tensor layout, and quantized matmul.
Technical interest: it exposes what frameworks hide: memory movement, cache behavior, data layout, numerical precision, and hardware utilization.
Measurements: tokens per second, peak memory, prefill latency, decode latency, correctness against reference outputs, and quantization error.
Edge Multimodal Agent
Explores: small VLMs, local speech models, embeddings, device inference, offline behavior, and local storage.
Technical interest: edge systems make latency, memory, power, privacy, and fallback behavior unavoidable.
Measurements: cold-start time, on-device latency, memory pressure, battery drain, thermal throttling, and recovery after network loss.
JEPA Playground
Explores: latent prediction over video, masked representation learning, action-conditioned prediction, and downstream planning tasks.
Technical interest: JEPA-style systems ask whether useful abstractions can be learned by predicting the world in representation space.
Measurements: representation quality, temporal consistency, downstream task transfer, anomaly detection, and planning success under distribution shift.
Diffusion Sampler From Scratch
Explores: DDPM, DDIM, classifier-free guidance, flow matching, rectified flow, schedulers, and noise trajectories.
Technical interest: generation becomes more legible when the sampler, guidance, conditioning, and scheduler are visible.
Measurements: step count, sample quality, prompt adherence, edit fidelity, compute cost, and failure cases across schedulers.
Video And Image Control Lab
Explores: masks, depth maps, pose, sketches, style adapters, consistency, and controllable edits.
Technical interest: useful generation depends on control, not only image quality. The hard part is preserving intent while changing the right pixels.
Measurements: edit fidelity, identity preservation, temporal consistency, mask leakage, and control strength.
LeRobot Physical AI Lab
Explores: robot datasets, teleoperation, imitation learning, action policies, simulation replay, and real-world failure.
Technical interest: robotics turns model quality into contact physics, calibration, latency, and data collection. Reality is an excellent reviewer. Rude, but fair.
Measurements: task success, reset count, calibration drift, action latency, sim-to-real gap, and policy degradation.
NVIDIA Physical AI Sandbox
Explores: world foundation models, simulation, synthetic data loops, robot policies, and edge deployment.
Technical interest: physical AI needs a loop between generated worlds, data curation, evaluation, and deployment. A model checkpoint alone is not enough.
Measurements: synthetic-to-real transfer, video realism, policy improvement, evaluation coverage, and edge inference latency.
Local-First Memory OS
Explores: capture, speech-to-text, diarization, embeddings, retrieval, consolidation, redaction, and permissioned agent loops.
Technical interest: ambient AI lives or dies on context and trust. Memory that ignores consent is not intelligence. It is a liability with a microphone.
Measurements: recall accuracy, retrieval quality, redaction quality, bystander handling, latency, storage growth, and user correction loops.
Edge Inference Optimizer Dashboard
Explores: quantization, batching, speculative decoding, KV cache policy, runtime choice, and device memory pressure.
Technical interest: deployed AI becomes an inference economics problem: latency, throughput, memory, energy, and cost per useful action.
Measurements: tokens per second, prefill/decode split, memory bandwidth, cache hit rate, energy per query, and p95 latency.
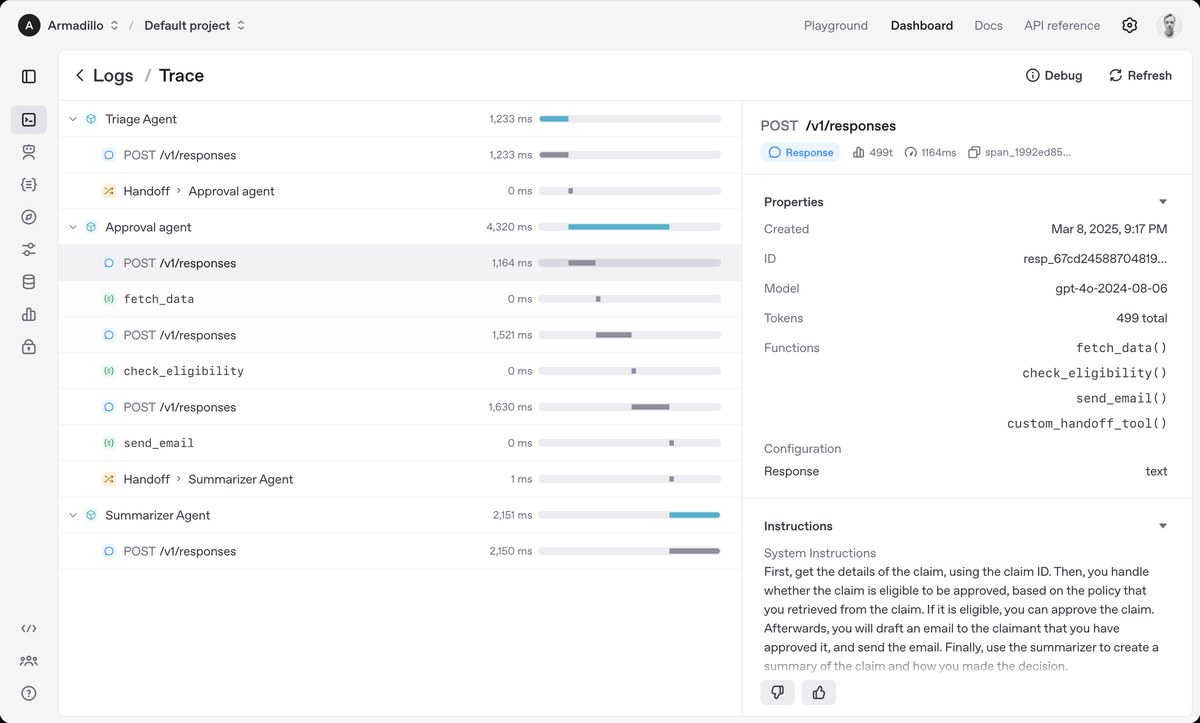
Real-Device Agent Eval Harness
Explores: tool use, MCP servers, stale context, slow tools, partial failure, network loss, memory conflicts, and user interruption.
Technical interest: agents are less interesting when everything works. Recovery behavior is where the system becomes real.
Measurements: task completion, recovery rate, tool latency, invalid action rate, human intervention count, and cost per completed workflow.
Explore project areas
Explores tensors, attention, tokenization, KV cache, quantization, sampling, and the runtime tradeoffs hidden by most frameworks.
Stack: Rust, safetensors, GGUF, tokenizer implementations, and benchmark harnesses.
Relevant repos: karpathy/llm.c, ggml-org/llama.cpp, huggingface/candle, karpathy/nanoGPT.
Ambient AI As A Technical Layer
Ambient AI is one of the more interesting areas because the core problem is not only model quality. It is context capture, memory formation, retrieval, consent, redaction, user correction, and action timing.
This is where NeoSapien's work informs my view. Conversation memory is not just a transcript problem. Once there is capture, diarization, memory generation, indexing, retrieval, and proactive assistance, the hard question becomes context governance: what enters memory, what stays local, what is deleted, what can be shared, and what the agent is allowed to do with it.
That is a systems problem. It touches models, product, privacy, latency, UX, and trust. The interesting version is not "summarize my transcript." The interesting version is a permissioned memory layer that stays useful without becoming creepy.
Ambient AI is not about wearing more computers. It is about deciding which context a system is allowed to remember, retrieve, and act on.
Diffusion Is Still Underrated As A Systems Topic
The public conversation around diffusion got weird because consumer image generation became so accessible. People started treating it like prompting software. Underneath, the technical stack is still rich: denoising, rectified flows, latent spaces, guidance, control, adapters, consistency, video, and evaluation.
A diffusion sampler workbench can make that stack visible. DDPM, DDIM, flow matching, rectified flow, classifier-free guidance, ControlNet, FLUX-style models, and Stable Diffusion 3.5-style systems all expose different parts of the generation process.
The useful output is not a gallery. It is a way to compare scheduler behavior, conditioning strength, edit fidelity, temporal consistency, and compute cost. Pretty images are allowed. They are not the measurement.
World Models Are A Deeper Bet Than Bigger Chat
JEPA-style work matters because it asks a deeper question than "what token comes next?"
Can a system learn useful representations of the world by predicting missing or future pieces of experience in latent space?
Meta's V-JEPA line makes this concrete for video. As of June 2026, NVIDIA frames Cosmos 3 as an open physical AI foundation model for reasoning, world generation, and action generation. Robotics labs are asking the same question from another angle: how can models understand the consequences of action before the robot breaks something expensive?
This area is hard to evaluate cleanly. Pixel prediction can look impressive while learning the wrong thing. Latent prediction can be useful while being visually opaque. That makes the repo, the eval task, and the visualization strategy unusually important.
Relevant Repos To Study
- Low-level runtimes: karpathy/llm.c, karpathy/nanoGPT, ggml-org/llama.cpp, and huggingface/candle
- Edge inference: pytorch/executorch, microsoft/onnxruntime, huggingface/transformers.js, and ml-explore/mlx
- JEPA and world models: facebookresearch/vjepa2, NVIDIA/Cosmos, and nvidia-cosmos
- Robotics and physical AI: huggingface/lerobot, NVIDIA/Isaac-GR00T, and pollen-robotics/reachy_mini
- Diffusion and control: huggingface/diffusers, black-forest-labs/flux, Stability-AI/sd3.5, and lllyasviel/ControlNet
- Agents and evals: modelcontextprotocol/servers, openai/openai-agents-python, and langchain-ai/open_deep_research
Open Problems Across The Stack
A few themes show up again and again.
- Measurement: many demos still lack latency traces, failure rates, cost curves, and stress tests.
- Locality: edge inference is improving, but local memory, local retrieval, and local privacy controls remain awkward.
- Control: generation systems are impressive, but exact editability and temporal consistency are still not solved.
- Embodiment: robotics exposes weak assumptions around data, calibration, actuation, and evaluation.
- Context: agents need better memory boundaries, better tool recovery, and better handling of stale information.
Fine-tuning will keep mattering. It is a practical tool. But the deeper project areas are often around the model: how it runs, where it runs, what it remembers, how it senses, how it generates, how it acts, and how anyone knows it worked.
That is the more interesting map.
Sources
- Karpathy llm.c, nanoGPT, and micrograd
- Hugging Face Candle, Transformers.js, Diffusers, and LeRobot
- llama.cpp, GGUF documentation, and PyTorch ExecuTorch
- ONNX Runtime, Apple MLX, and Burn Rust deep learning framework
- Meta V-JEPA 2, Meta V-JEPA 2 paper page, V-JEPA 2 paper, and A Path Towards Autonomous Machine Intelligence
- NVIDIA Cosmos 3, NVIDIA Isaac GR00T, NVIDIA Jetson Thor, and NVIDIA IGX Thor
- Black Forest Labs on Hugging Face, Black Forest Labs, and Stable Diffusion 3.5
- LeRobot GitHub repository, LeRobot models and datasets on Hugging Face, and Awesome LeRobot
- Inline source images use assets from the official llama.cpp, V-JEPA 2, FLUX, LeRobot, Isaac GR00T, and OpenAI Agents SDK repositories.